Computer Vision Platform
A unified no-code machine learning platform for the training of image classification & object detection models.


I want to:
Image Classification
Models for automatic recognition, categorization & tagging of images or objects in them.
CATEGORIZATION & TAGGING
Train Your Own Visual AI

Define your own categories & tags, link them to training images, and train custom image recognition models.
Automate all image classification with computer vision: tagging, sorting, filtering, and even quality control or recommendations of the items or images from your collection.
DELEGATE ROUTINE TASKS TO AI
No-Code Machine Learning
Working with Ximilar computer vision platform doesn’t require coding skills. You easily train & chain your models with a few clicks.
AI running on Ximilar cloud processes large volumes of data 24/7. You can connect via API and integrate both ready-to-use and custom models into your system.

Enrich
your data with detailed information

Delegate
routine tasks to consistent AI

Save
time and resources with automation
WHAT IS CATEGORIZATION?
Assign a category to each image
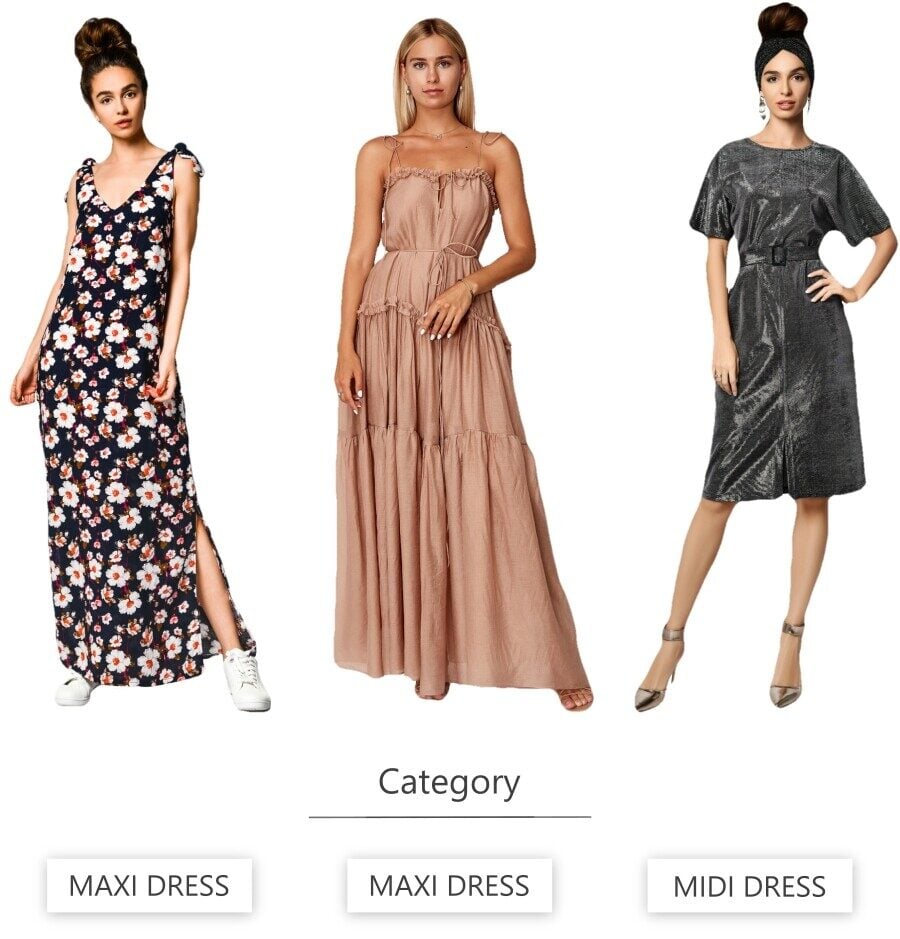
Image categorization assigns each image a category, such as a maxi dress or midi dress. The categories are visually distinctive, and each image belongs only to one category.
WHAT IS TAGGING?
Tag every image with many tags
Define a set of tags for the features & objects that should be recognized in your images, and train a custom tagging model able to provide tags for each image in your collection.

Skip the setup with ready-to-use solutions
Check out our solutions for fashion, home decor, collectibles, and more.
They can be used right away or combined with custom models.
Image Regression
A specialized recognition system for evaluation or grading.
IMAGE REGRESSION
Automatic Prediction of Size, Age, or Rating From Images

The image regression predicts numerical values within a defined range from your images. It is used in quality control, and to estimate values such as age, size, worn-out level, or rating.
You can train regression models under Image Classification in our App (create a new task: regression). We can also build a value prediction system tailored to your use case.
Object Detection
Object detection automatically finds different types of objects & marks them with bounding boxes.

OBJECT DETECTION
Train AI to Spot Any Object
Train custom object detection models (CenterNet) to identify any object, such as people, cars, particles in the water, imperfections of materials, or objects of the same shape, size, or colour.
Object detection can work both independently or combined with other tasks, such as automatic tagging.
Q & A
How do I prepare the training data?
The training of object detection models requires bigger datasets and more training time. It begins with data annotation – the manual marking of objects with bounding boxes. You can use the same dataset as for Categorization & Tagging model training.
Q & A
How do you work with my data?
During the training of custom image recognition models, your annotated images are divided into two groups. Apart from the training set, there is a smaller validation set, which is used to evaluate the accuracy of the model before the deployment. You can also upload another independent test set.
Data Annotation Tools
App
You can annotate your training images directly in Ximilar App, where you train the models.
Annotate
Level up your data annotation work with a professional tool for quick annotation in a team.
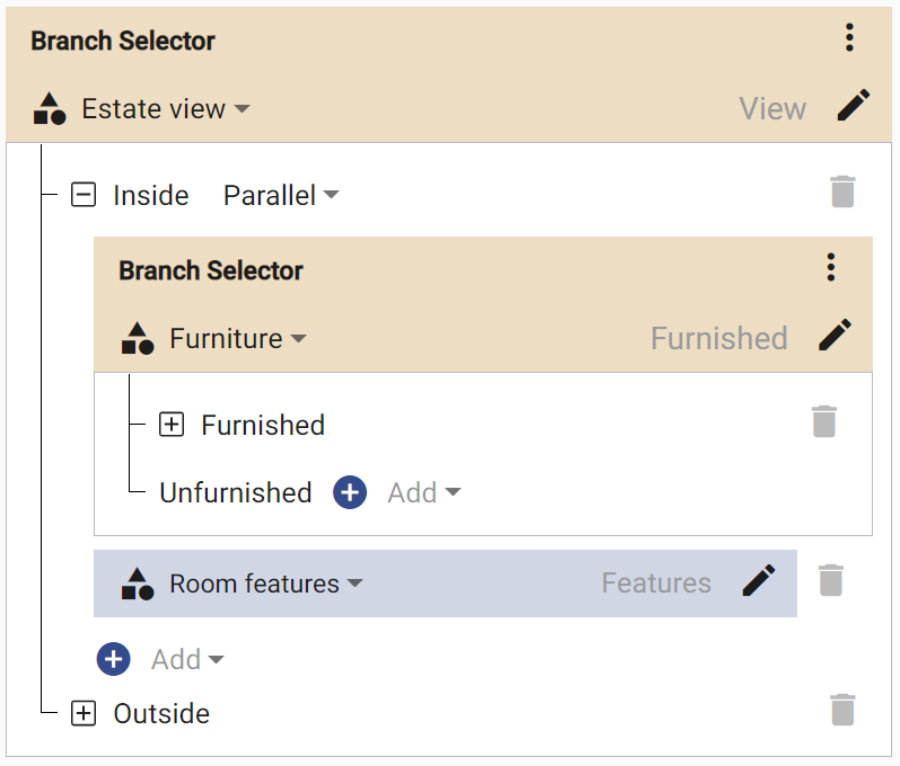
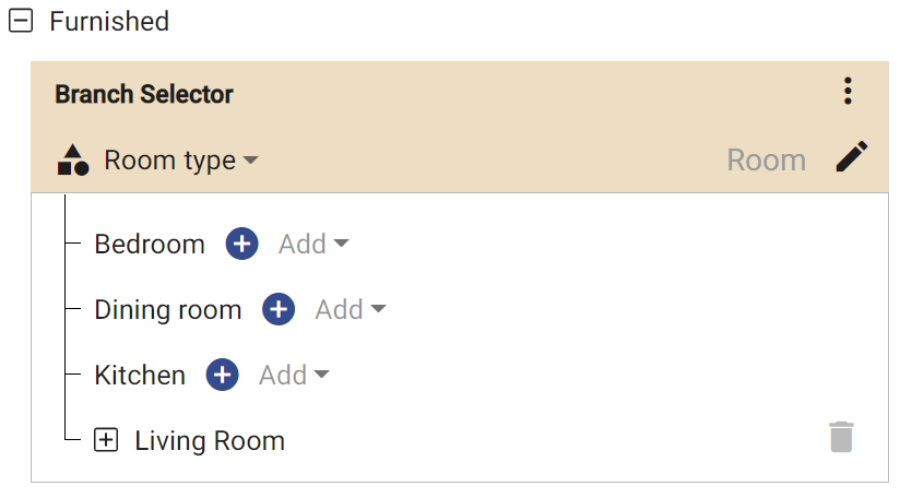
Flows: Combine Your Models
The key to the management of complex image databases is the interaction of more different models.
MODELS WORKING TOGETHER
Divide Complex Problems Into Simple Tasks
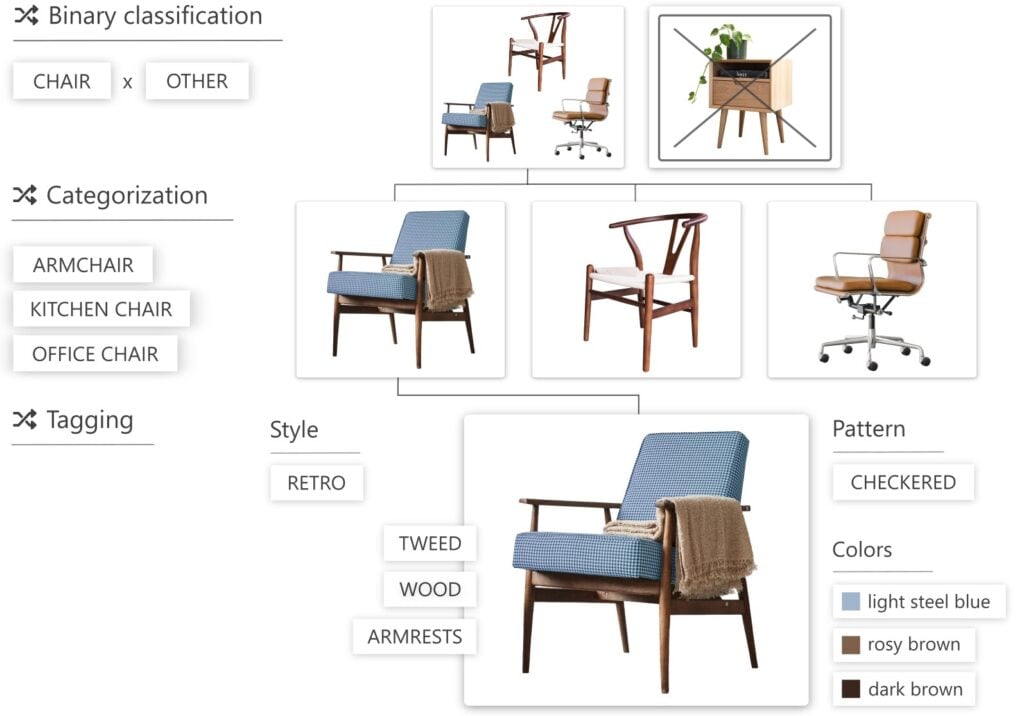
With Flows, the machine learning models can be combined and chained in a sequence.
Each image travels through the sequence of your models until it is properly processed and tagged. Based on Flows, you also get suggestions when annotating the images.
ENDLESS POSSIBILITIES
Change & Modify Your Tasks Anytime
- Combine custom & ready-to-use solutions
- Re-train, add or remove any unit
- Recognize only the detected objects
- Call more tasks (models) in one API call or multiple recognition tasks in parallel
- Add endless nested flows into a primary flow
- Use one flow in several places
Build rich hierarchy
Define a flow with a few clicks, then use it for both training & automation
Play with the features
Add, remove, or change components, duplicate & modify your flows
Make changes on the fly
Flow structure handles any changes to both dataset and connected models
EXAMPLE: REAL ESTATE
Conditional image processing
Imagine you are building a real estate website. The first models in your flow can filter out all images that don’t meet certain selection criteria. In this case, it would be the pictures without any real estate, rooms, or furnishing.
EXAMPLE: REAL ESTATE
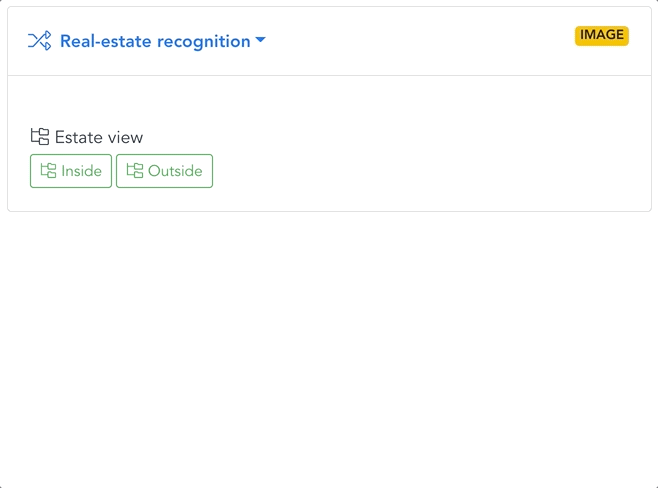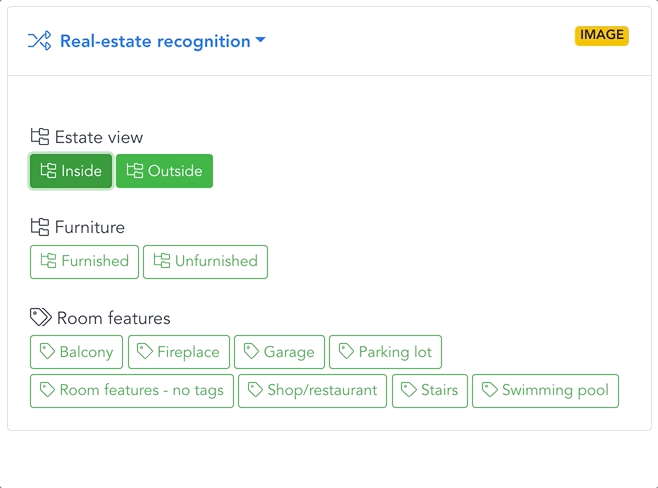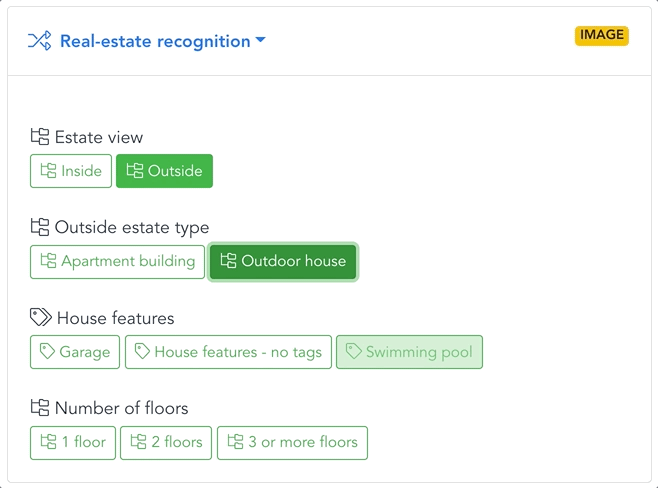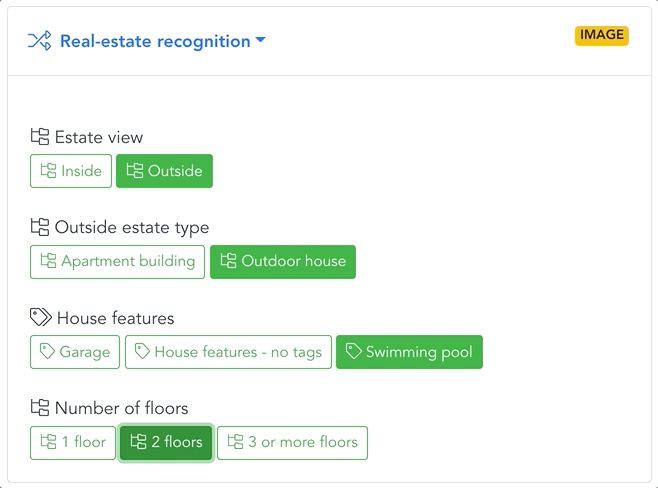
Automatic filtering, sorting & tagging
Images can then be gradually sorted with an increasing level of precision. The first task (model) separates apartments and houses. Then, the apartments are sorted by room type, design, and furniture decor, and the houses by features such as architecture, area, garden or swimming pool.
Be Ahead of the Competition
Unlimited number of images
There are no limits on number of images per model/label
Use one image for many models
You can use the same images for the training of different models
Built-in data augmentation
You don’t have to prepare or multiply the training data in advance
No fees for training time
Unlike the competition, Ximilar doesn’t charge you for the training time
No fees for idle time
The same goes for idle time – you don’t pay anything
Cashing deployed models
Image processing takes 300 ms, as opposed to 2-3 s at other platforms

TECHNOLOGY STACK
We use state of the art neural network models & machine learning techniques
Our AI is improving constantly, so you always have up-to-date technology. Each model has millions of parameters that can be processed by CPU or GPU.
Our intelligent algorithm picks and uses the best performing models. We are using the latest technologies for machine learning as TensorFlow or OpenVINO.
Frequently Asked Questions
What means categorization, tagging, tags, and labels? What is the difference between categorization and tagging?
Automatic categorization is a process in which every image is assigned to a category. It is powered by AI which was trained to recognize the categories of images. Each image belongs only to one, visually distinctive, category – for example, dress vs. trousers. E-shops typically use a hierarchical taxonomy of products, so they work with both categories and sub-categories.
Automatic image tagging is a process in which each image is tagged by AI based on attributes recognized in the image. For example, when you upload a photo of a dress on a model, the dress will be put into the category dresses and subcategory casual dresses, and tagged with tags describing its colour, pattern, design, style, material, length, and other attributes.
In the case of categorization & tagging, a label is a term describing both categories and tags. Object Detection, on the other hand, works with detection labels, labelling the detected objects, people, or animals in the images.
Ximilar provides several categorization and tagging services. You can either use our ready-to-use Image Recognition services (such as Fashion Tagging or Home Decor & Furniture Tagging) or train your own from scratch on Ximilar computer vision platform. Both ready-to-use services and custom tasks can cooperate through Flows.
How can I train my own categorization & tagging model?
The training of machine learning models is available to everyone. First, log in to Ximilar computer vision platform, then check our comprehensive guide on How to Build Your Own Image Recognition API.
Go to:
- How Ximilar technology works?
- Is there a difference between a task and a model?
- Can I use one task (model) in multiple Flows?
- How do I connect to Ximilar API?
- How do I test the accuracy of my Image Recognition and Object Detection models? What are evaluation metrics?
- What is A/B testing of machine learning models?
- What is a machine learning loop?
Is the number of labels per task limited?
Technically, there is no limitation to the number of labels per task. However, using hundreds or more labels would require a very large volume of training data. In such cases, we recommend creating a hierarchy of models and combining them with Flows.
Can I combine machine learning models or put them in a sequence?
Yes! The basic principle of our solutions lies in separate machine learning models, which work together or in a modular structure of Flows. Flows enable you to chain your models in a sequence, combine them, put them in a hierarchical structure, and implement conditional processing.
What is image annotation, and when do I need it?
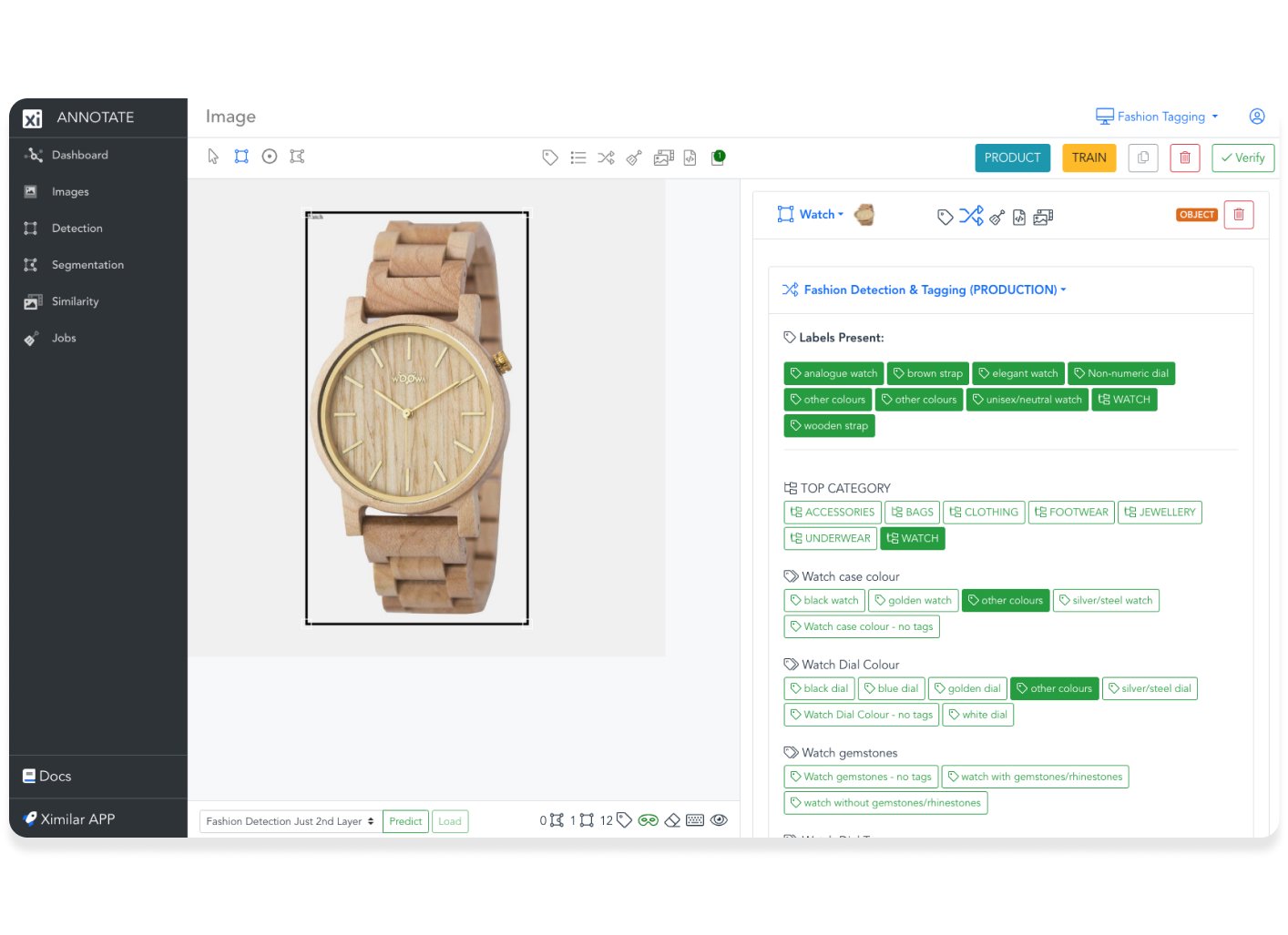
Object detection models’ training requires the training dataset to be annotated. The annotation of images means marking the objects we need to be detected with bounding boxes. Precise and consistent image annotation is a key to successful object detection solutions. It is done manually, but can be assisted by the AI. At the Ximilar platform, users can annotate their training images both in the App and in a dedicated interface Annotate.
Go to:
What is Annotate? How does it work?
Annotate is an advanced image annotation tool by Ximilar built for the annotation of large volumes of training data effectively, precisely, and fast. It is web-based and connected to the same back-end & database as Ximilar App. Therefore, all changes you do in Annotate will also be visible in your workspace in App. It is connected to Rest API with Python SDK, and annotated data are queried.
You can upload images through the App, and annotate them in Annotate. You can work in a team, assign annotating jobs to your teammates, and set how many times each image should be checked.
What is the difference between annotation in Ximilar App and Annotate?
The basic principle of image annotation in Ximilar App and Annotate is the same: you view an image, pick which object detection task should predict the objects in the image, and then check the position of bounding boxes or draw new ones. You can check the assigned labels (categories and tags) and add new ones from the hierarchy (in Annotate) or even create new ones (in App). You can use both interfaces to create and train your tasks.
Ximilar App is great for creating entities such as labels and tasks, uploading data, model training, task management, and batch management of images (bulk actions for labelling and filtering). If you need to add new labels (tags and categories) even while annotating your images, you can do it in App.
If you need to annotate a lot of images, and you already have a hierarchy of labels (in App), we recommend uploading images there and then working in Annotate. The main difference is Annotate enables you to process large amounts of training images precisely, but fast, with several advanced features.
Does Annotate support work in a team or multiple accounts?
Your company account can have many workspaces, each for one project. Your team members can get access to different workspaces. Also, everyone can switch between the workspaces in the App as well as in Annotate (top right, next to the user icon). Did you know, that the workspaces are also accessible via API? Check out our documentation and learn how to connect to API.
How do I test the accuracy of my Image Recognition and Object Detection models? What are evaluation metrics?
Each of your models automatically goes through testing on an evaluation dataset during the training phase. You can also add a separate test set.
You can test your models both via standard Rest API endpoint and in Ximilar App. Click on Tasks, scroll down to Models and click on a magnifying glass to view the details about a particular model. There you can check the evaluation metrics (accuracy, precision, recall, confusion matrix, and failed images). Based on these metrics, you can further iterate and improve your training dataset to make your model more robust. We are also able to change the architecture of the neural network if needed and improve the robustness for your specific data.
You can also test the accuracy of your model on a particular image. Drag & drop the image or copy its URL to Test under your service.
What is A/B testing of machine learning models?
A/B testing is a technique to test and decide whether the new version of your machine learning model performs better than the previous one based on selected metrics.
What is mAP metric of object detection models?
The mAP, or mean average precision (AP) is an evaluation metric describing the precision of your object detection models. It is calculated from IOU (the Intersection Over Union is used to determine whether the bounding box was correctly predicted), Precision, Recall, Precision-Recall Curve, and AP. You can find the mAP of your object detection model per label in your workspace under Object Detection: Tasks: Models in the detail of the particular model.
Is there a difference between a task and a model?
The task is the latest and the most accurate version of the machine learning model you trained. Read How Ximilar technology works? for details.
What is a machine learning loop?
Any image that is processed by a deployed machine learning model can be saved to the workspace and used to retrain the model to improve it. The retraining is done manually after annotators check these new images. Then the new, better and more accurate, version of the model is deployed. This loop improves the accuracy of your model in the long term, especially if the character of the data changes over time (e.g. the lightning of the scene changes dramatically). See pricing for details about availability.
What is custom image recognition?
Image recognition is a technology able to recognize an image (e.g., a picture of a shoe) and describe its appearance with tags (e.g., leather, brown, women’s shoes, high heels).
Ximilar provides several off-the-shelf solutions for the detection, recognition, tagging and sorting of specific image data, such as stock photos, home decor and furniture images, fashion photos, or trading and collectible cards.
Anyone can create and train their own custom image recognition models on Ximilar’s computer vision platform. Namely, you can train:
- image classification models: categorization & tagging, image regression (value prediction)
- object detection models
It requires no coding experience. The custom models can be easily combined with existing ready-to-use solutions with Flows.
Object Detection requires manual annotation of training data, which can be done both in our App and dedicated interface Annotate.
Go to:
- Start for free now
- Computer Vision Platform
- Annotate
- Flows
- Read more about Flows
- Explainable AI: What is My Image Recognition Model Looking At?
- Which services does Ximilar provide, and what are the differences between them?
- How Ximilar technology works?
- How can I train my own categorization & tagging model?
- Can I combine machine learning models or put them in a sequence?
- Can I combine visual search algorithms with custom models created with Ximilar platform?
What is the use of image recognition in retail?
In retail, image recognition is pivotal in optimizing operations depending on visual data processing. One significant application lies in inventory management, where it automates tracking products and stock levels, streamlining restocking processes and minimizing manual effort.
Additionally, image recognition helps with consumer research, enabling retailers to gain insights into customer demographics and behaviour within physical stores. This information aids in optimizing store layouts, product placements, and staffing strategies to enhance the overall shopping experience.
Image recognition also supports personalized marketing initiatives by analyzing customer preferences and purchase history, allowing e-shops to tailor promotions and recommendations accordingly. This personalized shopping experience fosters stronger customer engagement and increases sales.
In many of these applications, image recognition works in tandem with visual search technology, which identifies visually similar products to items detected in product photos and real-life images.
In which fields does image recognition help?
Image recognition technology finds widespread application in diverse fields such as healthcare, retail, and security systems.
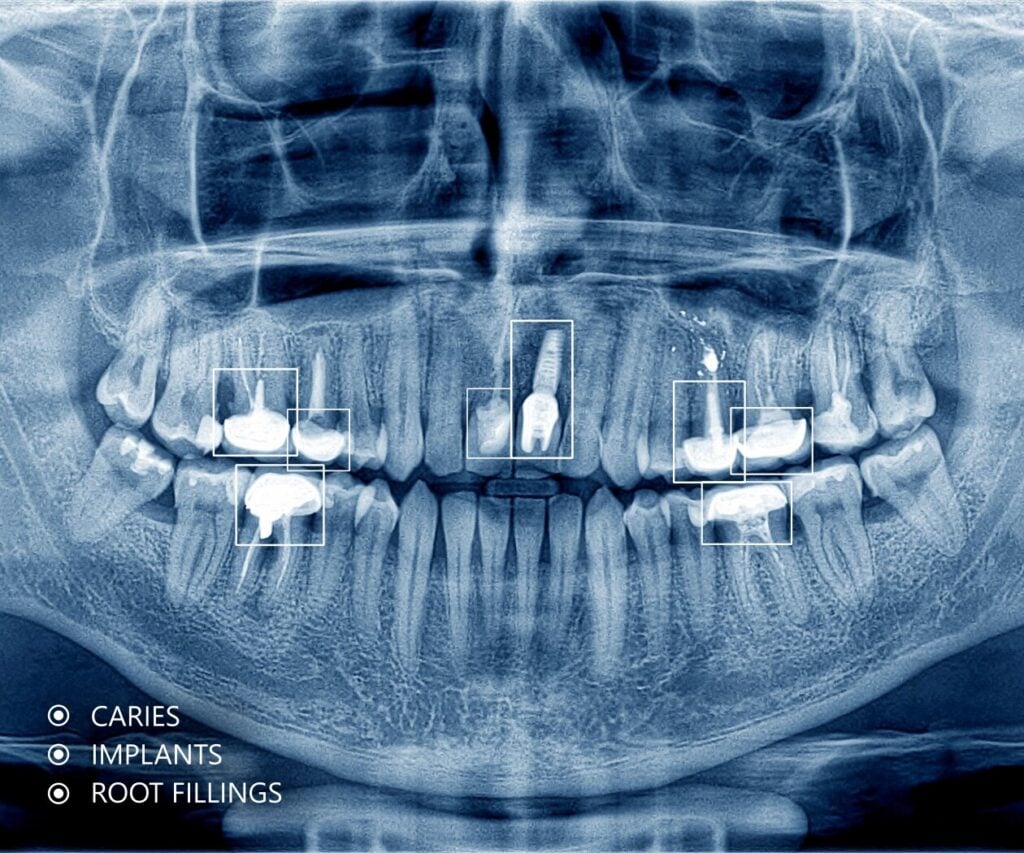
In healthcare, it aids in the interpretation of medical images, assisting clinicians in diagnosing diseases and identifying anomalies with greater precision. Read about some of our use cases here.
Similarly, in retail, image recognition streamlines checkout processes, and, together with visual search, enhances customer experience through personalized recommendations.
In security, it strengthens surveillance systems by enabling real-time monitoring, threat detection, and facial recognition.
This technology is also essential for autonomous vehicles, enabling them to perceive their surroundings through cameras and sensors, recognize objects, pedestrians, and road signs, and make real-time decisions for safe navigation.
Additionally, image recognition systems help in both research and applied sciences. For instance, in biological research, microscopy image analysis and wildlife conservation. It plays a crucial role in monitoring and protecting endangered species. It enables researchers and conservationists to analyze vast amounts of camera trap data efficiently, identifying and tracking individual animals, assessing population dynamics, and detecting potential threats such as poaching or habitat loss.
Image recognition aids satellite imagery analysis, especially in monitoring vegetation coverage crucial for sectors like insurance and agriculture. LAICA, by World From Space (WFS) and Ximilar, addresses this, using deep learning to merge satellite data for daily vegetation monitoring despite cloud cover challenges.
In social media, image recognition facilitates image tagging and content moderation.
What factors determine the accuracy of the image recognition system?
The two key factors determining the accuracy of the image recognition task are the complexity of the task and the quality and quantity of the training data available. Some tasks achieve high precision easily, while others demand extensive data and effort for even moderate accuracy. The quality and accuracy of all your models can be tested, compared and improved over time on our platform. Learn more in our articles and reach out to us anytime to discuss your unique use case.
What image classification techniques does the Ximilar platform offer?
Our platform enables you to get and deploy models for image categorization (which involves assigning photos or detected objects into categories), image or product tagging (assigning more tags to each image or product, also known as multi-label prediction) and value regression (continuous value prediction from images and videos; for instance, a person’s age).
How image recognition works?
Image recognition allows computers to understand and classify images by analyzing their content. It helps with interpreting, tagging (enrichment with additional metadata), or categorization (sorting into groups) of images.
For example, if you train a dog vs. cat recognition model, and provide it with a folder of mixed pictures, it will be able to distinguish between cats and dogs, and thus sort the images into two separate folders.
It is used in various applications including medical diagnosis, autonomous vehicle systems (object recognition) or security systems (like facial recognition). The accuracy, speed, and efficiency of such systems continue to improve with advancements in artificial intelligence and machine learning techniques and depend on factors such as the quality of training datasets. Deep learning algorithms, particularly convolutional neural networks (CNNs), are commonly used for image categorization tasks.
Ximilar provides several off-the-shelf solutions for classifying specific image data, such as stock photos, home decor and furniture images, fashion photos, or trading and collectible cards. Custom models can be easily trained on our platform. Read the articles in our blog to learn about image recognition technology.
What are Flows?
Flows are a technology for chaining, combining and building a hierarchy of tasks for complex visual AI systems. It was developed by Ximilar to make the building of visual AI solutions easier and accessible without the need for coding. We use Flows to streamline complex image processing.
Which services can I combine with Flows? What are Actions?
Flows were made to combine different tasks into complex image processing systems. A Flow is built by adding the following actions:
- Branch Selector – contains an image recognition task; based on the recognition, your images are then processed by one or more branches of your Flow
- Recognition – performs an image recognition task and provides an output as specified by the user
- Detection – performs an object detection task, provides bounding boxes, and other outputs as specified by the user
- Object Selector – performs an object detection task; the detected objects are then analyzed separately by other actions
- Ximilar Service – calls any of the Ready-to-use Image Recognition services
- List – performs a list of actions with images (in sequence or simultaneously)
- Nested flow – calls another Flow
Go to:
Can I use one task (model) in multiple Flows?
Yes, one task (machine learning model) can be used in multiple Flows. Just add the right type of action in your Flow and then pick your task from the selection list.
What is the use of image recognition in healthcare?
Image recognition helps optimize diagnostics, treatment, as well as patient care by employing advanced AI algorithms to rapidly analyze medical imagery. It facilitates early disease detection, personalized treatment plans, and efficient workflows for healthcare providers. Key applications include diagnostic imaging and disease detection, such as analyzing X-ray or microscopy images, as well as providing surgical assistance. Additionally, the technology helps with other vital use cases such as drug discovery and health data analysis.
Can I have multiple Flows?
Flows are available to the users of all pricing plans. Check our Pricing for details.
Go to:
Is training, deployment and using of my Image Recognition tasks charged?
No, the training of custom image recognition models on Ximilar platform is completely free, as well as deploying your solutions and making them accessible to the end users. Also, unlike the competition, Ximilar does not charge the customers for idle time or training time, and the basic scheme for our App users is Free. With Ximilar, you only pay for the actual usage of the services – read about API calls & credits.
I know what I need, but I’m not sure how to build a Flow.
Need help with setup? Watch the video tutorial or read the guide. If you need a solution tailored to your business, feel free to contact us. We can prepare a demo on your data and deploy the system for you.
What do I pay for when using the Flows?
Using Ximilar services consumes API credits. Ximilar provides three pricing plans with different monthly API credit supplies, including a free scheme with 3,000 free credits. Creating a Flow and chaining tasks don’t cost any API credits. There are, however, limitations as to how many Flows you can have.
Go to:
How fast and efficient is the image recognition process?
The speed typically ranges from 5 to 100 milliseconds per image for basic image classification and detection models. This timeframe varies based on factors such as input resolution, connectivity, and the speed of the image CDN used. Our platform’s models are generally very fast, and they can be fine-tuned for even greater efficiency on specialized hardware like GPUs and smartphones.
Tips & Tricks
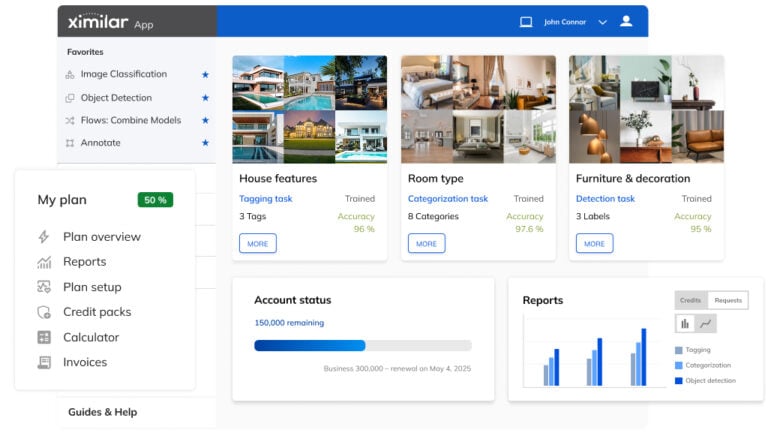
Getting Started with Ximilar App: Plan Setup & API Access
Ximilar App is a way to access computer vision solutions without coding and to gain your own authentication key to use them via API.

Get an AI-Powered Trading Card Price Checker via API
Our AI price guide can be used for value tracking of cards and comic books, offering accurate pricing data and their history.

Identify Comic Books & Manga Via Online API
Get your own AI-powered comics and manga image recognition and search tool, accessible through REST API.
Get Image Recognition API Now
We take care of the complexity behind and wrap it in a few lines of code.
curl -H "Content-Type: application/json" -H "authorization: Token __API_TOKEN__" https://api.ximilar.com/recognition/v2/classify -d '{"task_id": "__TASK_ID__", "version": 2, "descriptor": 0, "records": [ {"_url": "https://bit.ly/2IymQJv" } ] }'import requests
import json
import base64
url = 'https://api.ximilar.com/recognition/v2/classify/'
headers = {
'Authorization': "Token __API_TOKEN__",
'Content-Type': 'application/json'
}
with open(__IMAGE_PATH__, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
data = {
'task_id': __TASK_ID__,
'records': [ {'_url': __IMAGE_URL__ }, {"_base64": encoded_string } ]
}
response = requests.post(endpoint, headers=headers, data=json.dumps(data)) if response.raise_for_status():
print(json.dumps(response.json(), indent=2))
else:
print('Error posting API: ' + response.text)$curl_handle = curl_init("https://api.ximilar.com/recognition/v2/classify");
$data = [
'task_id' => __TASK_ID__,
'records' => [
[ '_url' => 'https://bit.ly/2IymQJv' ],
[ '_base64' => base64_encode(file_get_contents(__PATH_TO_IMAGE__)) ]
]
];
curl_setopt($curl_handle, CURLOPT_CUSTOMREQUEST, "POST");
curl_setopt($curl_handle, CURLOPT_POSTFIELDS, json_encode($data));
curl_setopt($curl_handle, CURLOPT_RETURNTRANSFER, true);
curl_setopt($curl_handle, CURLOPT_FAILONERROR, true);
curl_setopt($curl_handle, CURLOPT_HTTPHEADER, array(
"Content-Type: application/json",
"Authorization: Token __API_TOKEN__",
"cache-control: no-cache",)
);
$response = curl_exec($curl_handle);
$error_msg = curl_error($curl_handle);
if ($error_msg) { // Handle error
print_r($error_msg);
} else { // Handle response
print_r($response);
}
curl_close ($curl_handle);Ximilar is a reliable & responsible partner in image AI. We deliver what we promise.
Contact us now- Easy setup
- •
- Expert team
- •
- Fast scaling