The Best Tools for Machine Learning Model Serving
An overview and analysis of serving systems and deployment methods for Machine Learning and AI models.


As the prevalence of AI in various industries increases, so does the need to optimize the machine learning model serving. As a machine learning engineer, I’ve seen that training models is just one part of the ML journey. Equally important as the other challenges is the careful selection of deployment strategies and serving systems.
In this article, we’ll delve into the importance of selecting the right tools for machine learning model serving, and talk about their pros and cons. We’ll explore various deployment options, serving systems like TensorFlow Serving, TorchServe, Triton, Ray Serve, and MLflow, and also the deployment of specific models such as large language models (LLMs). I’ll also provide some thoughts and recommendations for navigating this ever-evolving landscape.
Machine Learning Models Serving Then and Now
When I first began my journey in the world of machine learning, the landscape was constantly shifting. The frameworks being actively developed and used at the time included Caffee, Theano, TensorFlow (Google) and PyTorch (Meta), all vying for their place in the world of AI. As time has passed, the competition has become more and more lopsided, with TensorFlow and PyTorch leading the way. While TensorFlow has remained the more popular choice for production-ready models, PyTorch has been steadily gaining in popularity, particularly within research circles, for its faster, more intuitive prototyping capabilities.
While there are hundreds of libraries available to train and optimize models, the most popular frameworks such as TensorFlow, PyTorch and Scikit-Learn are all based on Python programming language. Python is often chosen due to its simplicity and the vast amount of libraries for data manipulation. However, it is not the fastest language and can present problems with parallel processing, threads and GIL. Additionally, specialized libraries such as spaCy and PyG are available for specific tasks, such as Natural Language Processing (NLP) and Graph Analysis, respectively. The focus was and still partially is on the optimization of models and architectures. On the other hand, there are more and more problems in machine learning models serving in production because of the large-scale adoption of AI.
Nowadays, even more complex models like large language models (LLM, GPT/LAMMA/BARD) and multi-modal models are in fashion which creates a bigger pressure on optimal model deployment, infrastructure environment and storage capacity. Making machine learning model serving and deployment effective and cheap is a big problem. Even companies like Microsoft or NVIDIA are actively working on solutions that will cut the costs of it. So let’s look into some of the best options that we as developers currently have.
The Machine Learning and DevOps Challenges
Being a Machine Learning Engineer, I can say that training a model is just a small part of the whole lifecycle. Data preparation, deployment process and running the model smoothly for numerous customers is a daily challenge and a major part of the job.
Deployment Strategies
In addition to having to allocate GPU/CPU resources and manage inference speed, the company deploying ML models must also consider the deployment strategy for the trained model. You could be deploying the ML model as an API, running it in a container, or using a serverless platform. Each of these options comes with its own set of benefits and drawbacks, so carefully considering the best approach is essential. When we have a trained model, there are several options on how to use it:
- Deploy it as an API endpoint, sending data in the request and getting results immediately in response. This approach is suitable for faster models that are able to process the data in just a few seconds.
- Deploy it as an API endpoint, but return just a promise or asynchronous response from the model. This is great for computational-intensive models that can take minutes or hours of processing. For example, generative models and upscaling models are slow and require this approach.
- Use a system that is able to serve it for you.
- Use the model locally on your data.
- Deploy models on Smartphones or IoT devices with feed from local sensors.
Other Challenges
The complexity of machine learning projects grows with variables such as:
- The number of models – It is common practice to use multiple models. For example, at this moment, there are tens of thousands of different ML models on the Ximilar platform.
- Model versions – You can train each of your models on different training data (part of the dataset) and mark it as a different version. Model versioning is great if you want to A/B test your ML model, tune your model performance, and for continuous model training.
- Format of models – You can potentially train and save your ML models in various formats. For instance, .h5 which is a Keras/TensorFlow format or .pt (PyTorch) or .onnx for ONNX Runtime. Usually, each framework supports only specific formats.
- The number of frameworks – Served ML models could be trained with different frameworks and their versions.
- The number of the nodes (servers) – Models can be hosted on one or multiple servers and the serving system should be able to intelligently load balance the requests on servers so that none of them is throttled.
- Models storage/registry – You need to store the ML models in some database or storage, such as AWS S3 or local storage
- Speed/performance – The loading time of models from the storage can be critical and can cause a slow inference per sample.
- Easy to use – Calling model via Rest API or gRPC requests, single-or-batch inference.
- Hardware specification – ML models can be deployed on Edge devices or PCs with various architectures.
- GPUs vs CPUs and libraries – Some models must be used only on CPUs and some require a GPU card.
Our Approach to the Machine Learning Model Serving
Several systems were developed to tackle these problems. Serving and deploying machine learning models has come a long way since we founded Ximilar in 2016. Back then, no system was capable of effectively serving hundreds of neural networks for inference.
So, we decided to build our own system for machine learning model serving, and today it forms the backbone of our machine-learning platform. As the use of AI becomes more widespread in companies, newer systems such as TensorFlow Serving emerge quickly to meet the increasing demand.
Which Framework Is The Best?
The Battle of Machine Learning Frameworks
Nowadays, each big tech company has their own solution for machine learning model serving and training. To name a few, PyTorch (TorchServe) and AITemplate by META (Facebook), TensorFlow (TFServing) by Google, ONNX runtime by Microsoft, Triton by NVIDIA, Multi-Model-Server by Amazon and many others like BentoML or Ray.
There are also tens of formats that you can save your ML model in, just TensorFlow alone is able to save into .h5, .pb, saved_model or .tflite formats, each of them serving a different purpose. For example, TensorFlow Lite is great for smartphones. It also loads very fast, so the availability of the model is great. However, it supports only limited operations and more modern architectures cannot be converted with it.
You can also try to convert models from PyTorch or TensorFlow to TensorRT and OpenVino formats. The conversion usually works with basic and most-used architectures. The TensorRT is great if you are deploying ML models on Jetson Nano or Xavier. You can achieve a boost in performance on Intel servers via OpenVino conversion or the Neural Magic library.
The ONNX Format
One notable thing is the ONNX format. The ONNX is not a library for training your machine learning models, ONNX is an open format for storing machine learning models. After the model training, for example, in TensorFlow, you can convert it to ONNX format. You are able to run this converted model via ONNX runtime on almost any platform, programming language, CPU architecture and with preferred hardware acceleration. Sometimes serving a model requires a specific version of libraries, which is why you can solve a lot of problems via ONNX.
Exploration is Key
There are a lot of options for ML model training, saving, conversion and deployment. Every library has its pros and cons, some of them are easy to use for training and development. Others, on the other hand, are specialized for specific platforms or for specific fields (computer vision, recommender systems or NLP).
I would recommend you invest some time in exploring all the frameworks and systems, before deciding which framework you would like to lock in. The competition is rough in this field and every company tries to be as innovative as possible to keep up with the others. Even a Chinese company Baidu developed their own solution called PaddlePaddle. At the end of the article, I will give some recommendations on which frameworks and serving systems you should use and when.
The Best Machine Learning Serving Tools
OK, let’s say that you trained your own model or downloaded one that has already been trained. Now you would like to deploy a machine-learning model in production. Here are a few options that you can try.

If you don’t know how to train a machine learning model, you can start with this tutorial by PyTorch.
Deploy ML Models With API
If you have one or a few models, you can build your own system for ML model serving. With Python and libraries such as Flask or Django, there is a straightforward way to develop a simple REST API. When the web service starts, it loads the model in the background and then every incoming request will call the model on the incoming data.
It could get problematic if you want to effectively work with GPU cards, and handle parallel requests. I would recommend packing the system to Docker and then running it in Kubernetes.
With Kubernetes, Docker and smart load-balancing as HAProxy such a system can potentially scale to bigger volumes. Java or Go languages are also good languages to deploy ML models.
Here is a simple tutorial with a sci-kit-learn model as REST API with Flask.
Now let’s have a look at the open-source serving systems that you can use out of the box, usually with a small piece of code or no code at all.
TensorFlow Serving
TensorFlow Serving is a modern serving system for TensorFlow ML models. It’s a part of TensorFlow Extended developed by Google. The recommended way of using the system is via Docker.
Simply run the Docker pull TensorFlow/serving (optionally TensorFlow/serving:latest-gpu if you need GPU support) command. Just run the image via Docker:
docker run -p 8501:8501
--mount type=bind,source=/path/to/my_model/,target=/models/my_model
-e MODEL_NAME=my_model -t tensorflow/servingNow that the system is serving your model, you can query with gRPC or REST calls. For more information, read the documentation. TensorFlow Serving works best with the SavedModel format. The model should define its signature_def_map which will define the inputs and outputs of the model. If you would like to dive into the system then my recommendation is videos by the team itself.
In my opinion, TensorFlow serving is great with simple models and just a few versions. The documentation, however, could be simpler. With advanced architectures, you will need to define the custom operations, which is a big disadvantage if you have a lot of models with more modern operations.
TorchServe
TorchServe is a more modern system than TensorFlow Serving. The documentation is clean and supports basically everything that TF Serving does, however, this one is for PyTorch models. Before serving a PyTorch model via TorchServe, you need to convert them to .mar packages. Basically, the .mar package tells the model name, version, architecture and actual weights of the model. Installation and running are also possible via Docker, and it is very similar to TensorFlow Serving.
I personally like the management of the models, you are able to simply register new models by sending API requests, list models and query statistics. I find the TorchServe very simple to use. Both REST API and gRPC are available. If you are working with pure PyTorch models then the TorchServe is recommended way.
Triton
Both of the serving systems mentioned above are tightly bound to the frameworks of the models they are able to serve. That is probably why Triton has a big advantage over them since it can serve both TensorFlow and PyTorch models. It is also able to serve OpenVINO, ONNX and TensorRT formats! That means it supports all the major formats in the machine learning field. Even though NVIDIA developed it, it doesn’t require a GPU card and can run also on CPUs.
To run Triton, simply pull it from the docker repository via the Docker pull nvcr.io/nvidia/tritonserver command. The triton servers are able to load models from a specific directory called model_repository. Each model is defined with configuration, in this configuration, there is a platform setting that defines a model format. For example, “tensorflow_graphdef” or “onnxruntime_onnx“. In this way, Triton knows how to run specific models.
The documentation is not super-easy to read (mostly GitHub README files) because it is in very active development. Otherwise, working with the models is similar to other serving systems, meaning calling models via gRPC or REST.
Ray Serve
Ray is a general-purpose system for scaling machine learning workloads. It primarily focuses on model serving and providing the primitives for you to build your own ML platform on top.
Ray Serve offers a more Pythonic way of creating your own serving system. It is framework-agnostic and anything that can be run via Python can be run also with Ray. Basically, it looks as simple as Flask. You define the simple Python class for your model and decorate it with a route prefix handler. Then you just call the REST API request.
import requests
from starlette.requests import Request
from typing import Dict
from ray import serve
# 1: Define a Ray Serve deployment.
@serve.deployment(route_prefix="/")
class MyModelDeployment:
def __init__(self, msg: str):
# Initialize model state: could be very large neural net weights.
self._msg = msg
def __call__(self, request: Request) -> Dict:
return {"result": self._msg}
# 2: Deploy the model.
serve.run(MyModelDeployment.bind(msg="Hello world!"))
# 3: Query the deployment and print the result.
print(requests.get("http://localhost:8000/").json())If you want to have more control over the system, Ray is a great option. There is a Ray Clusters library which is able to deploy the system on your own Kubernetes Cluster, AWS or GCP with the ability to configure the autoscaling option.
MLflow
MLflow is an open-source platform for the whole ML lifecycle. From training to evaluation, deployment, tracking, model monitoring and central model registry.
MLflow offers a robust API and several language bindings for the whole management of the machine learning model’s lifecycle. There is also a UI for tracking your trained models. MLflow is really a mature package with a whole bundle of components that your team can use.
Other Useful Tools for Machine Learning Model Serving
- Multi-Model-Server is a similar system to the previous ones. Developed by the Amazon AWS team, the system is able to run models trained with MXNet or converted via ONNX.
- BentoML is a project very similar to MLflow. There are many different tools that data scientists can use for training and deployment processes. The UI looks a bit more modern. BentoML is also able to automatically generate Docker images for your models.
- KServe is a simple system for managing and scaling models on your Kubernetes. It solves the deployment, and autoscaling and provides standardized inference protocol across ML frameworks.
Cloud Options of AWS, GCP and Azure
Of course, every big tech player provides cloud platforms to host and serve your machine learning models. Let’s have a quick look at a few examples.
Microsoft is a big supporter of ONNX, so with Azure Machine Learning services, you are able to deploy your models to the cloud via Python or Azure CLI. The process requires an entry script in Python with two methods: init for initialization of your model and run for inference. You can find the entire workflow in Azure development documentation.
The Google Cloud Platform (GCP) has good support for TensorFlow as it is their native framework. However, Docker deployment is available, so other frameworks can be used too. There are multiple ways to achieve the deployment. The classic way will be using the AI Platform prediction tool or Google Cloud Run. There is also a serverless HTTP endpoint/function, which serves your model stored in the Google Cloud Storage bucket. You define your function in Python with the prediction method and loading of the model.
Amazon Web Services (AWS) also contains multiple options for the ML deployment process and serving. The specialized system for machine learning is Amazon Sagemaker.
All the big platforms allow you to create your own virtual server instances. Create your Kubernetes clusters and use any of the systems/frameworks mentioned earlier. Nevertheless, you need to be very careful because it could get really pricey. There are also smaller players on the market such as Banana, Seldon and Comet ML for training, serving & deployment. I personally don’t have experience with them but they are becoming more popular.
Large Language (LLMs) and Multi-Modal Models in Production
With the introduction of GPT by OpenAI a new class of AI models was introduced – the large language models (LLMs). These models are extremely big, trained on massive datasets and deployed on an infrastructure that requires a whole datacenter to run. “Smaller” – usually open source version – models are released but they also require a lot of computational resources and modern servers to run smoothly.
Recently, several serving systems for these models were developed:
OpenLLM by BentoML is a nice system that supports almost all open-source models like Llama2. You can just pick one of the models and run the following commands to start with the serving and query the results:
openllm start opt
export OPENLLM_ENDPOINT=http://localhost:3000
openllm query 'Explain to me the difference between "further" and "farther"'- vLLM project is a Python library that can help you with the deployment of LLM as an API Server. What is great is that it supports OpenAI-Compatible Server, so you can switch from OpenAI paid service easily to open source variant without modifying the code on the client. This project is being developed at UC Berkeley and it is integrating new techniques for fast inferencing of LLMs.
SkyPilot – is a great option if you want to run the LLMs on cloud providers such as AWS, Google Cloud or Azure. Because running these models is costly, SkyPilot is able to pick the cheapest provider automatically and launch it as an endpoint.
Ximilar AI Platform
Last but not least, you can use our codeless machine-learning platform. Instead of writing a lot of code, training and deploying an ML model by yourself, you can try it in the Ximilar App. Training image classification and object detection can be done both in the browser App or via API. There is every tool that you would need in the ML model development stage, such as training data/image management, labelling tools, evaluation of your models on testing and training datasets, performance metrics, explanation of models on specific images, and so on.
Ximilar’s computer vision platform enables you to develop AI-powered systems for image recognition, visual quality control, and more without knowledge of coding or machine learning. You can combine them as you wish and upgrade any of them anytime.
Once your model is trained, it is deployed as a REST API endpoint. It can be connected to a workflow of more machine learning models working together with conditions like if-else statements. The major benefit is you just connect your system to the API and query the results. All the training and serving problems are solved by us. In the end, you will save a lot of costs because you don’t need to own or rent your infrastructure, serving systems or specialized software engineering team on machine learning.
We built a Ximilar Platform so that businesses from e-commerce, healthcare, manufacturing, real estate and other areas could simply develop their own AI models without coding and with a reasonable budget. For example, on the following screen, you can see our task management for the trading cards collector community.
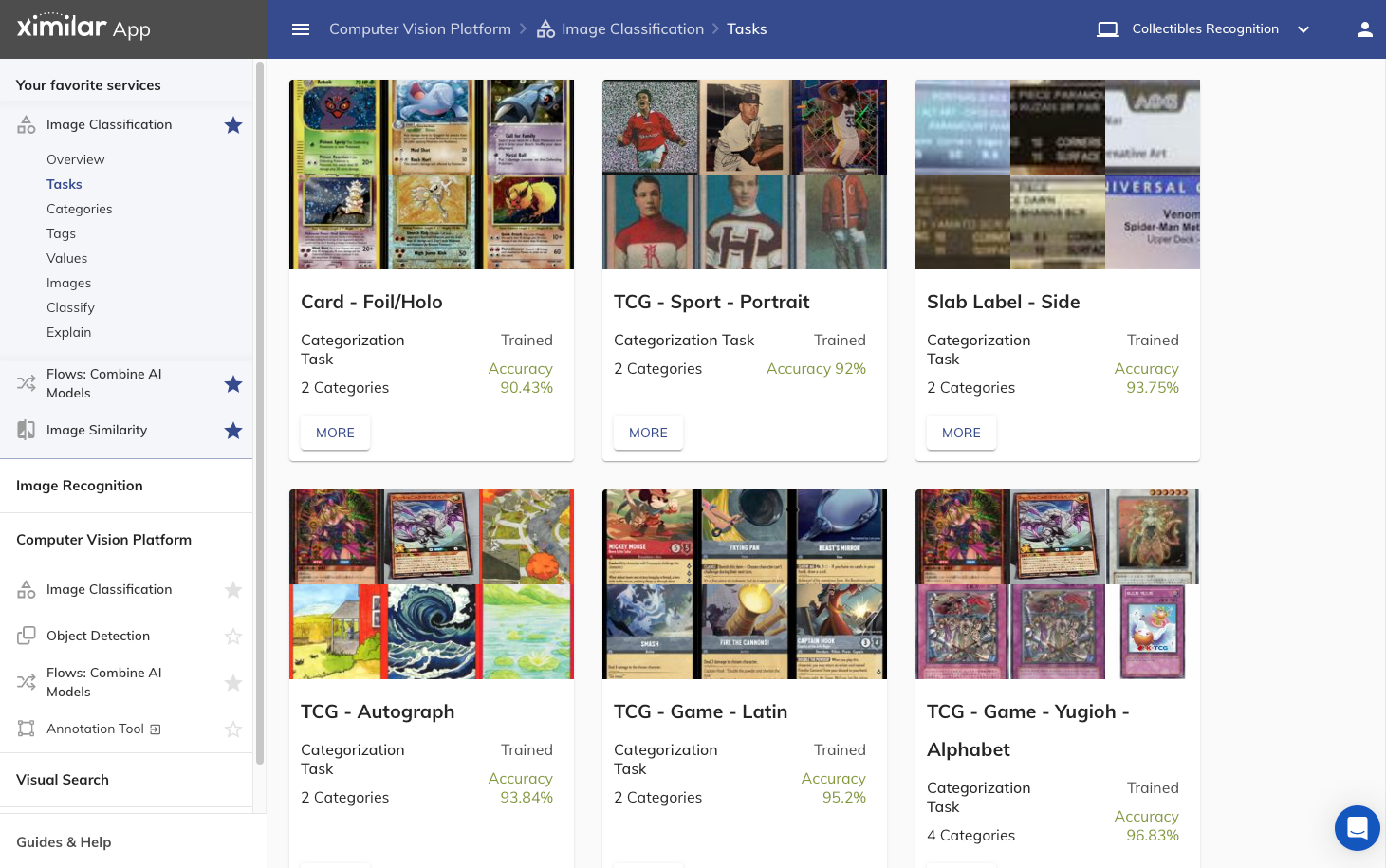
The great thing is that everything is manageable via REST API requests with JSON responses. Here is a simple curl command to query all models in production:
curl --request GET
--url https://api.ximilar.com/recognition/v2/task/
--header 'Content-Type: application/json'
--header 'authorization: Token APITOKEN'Deployment of ML Models is Science
There are a lot of systems that try to make deployment and serving easy. The topic of deployment & serving is broad, with many choices for hardware infrastructure, DevOps, programming languages, system development, costs, storage, and scaling. So it is not easy to pick one. If you would like to dig deeper, I would suggest the following content for further reading:
For the performance test of serving systems, I recommend a post from Biano that includes testing scripts.
- A nice overview of all the deployment systems is also in a video lecture on the Full Stack Deep Learning course.
My Final Tips & Recommendations
Pick a good framework to start with
Doing machine learning for more than 10 years, my advice is to start by picking a good framework for model development. In my opinion, the best choice right now is PyTorch. Using it is easy and it supports a lot of state-of-the-art architectures.
I used to be a fan of TensorFlow for a long time, but over time, its developers were not able to integrate modern approaches. Also, the backward compatibility is often disrupted and the quality of code is getting worse which leads to more and more bugs in the framework.
Save your models in different formats
Second, save your models in different formats. I would also recommend using ONNX and OpenVino here. You never know when you will need it. This happened to me a few times. We needed to upgrade the server and systems (our production environment), but the new versions of libraries stopped supporting the specific format of the model, so we had to switch to a different one.
Pick a serving system suitable to your needs
If you are a small company, then Ray Serve is a good option. Bigger companies, on the other hand, have complex requirements for development and robust infrastructure. In this case, I would recommend picking more complex systems like MLFlow. If you would like to serve the models on the cloud, then look at a multi-model server. The choice is really based on the use case. If you don’t want to bother with all of this then try our Ximilar Platform, which is a solution model optimization, model validation, data storage and model deployment as API.
I will keep this article updated and if there is some new perspective serving system I will be more than happy to mention it here. After all, machine learning is about constant progress, and that is one of the things I like about it the most.

Tags & Themes
Related Articles
How to Fine-Tune a Vision Language Model Without Writing Code
Ximilar’s no-code VLM platform lets you fine-tune small, private AI models and deploy them on any device – no ML expertise required.
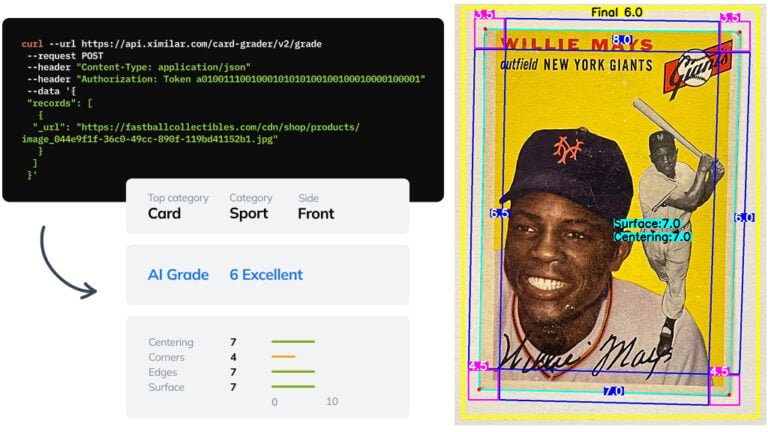
Automate Card Grading With AI via API – Step by Step
A guide on how to easily connect to our trading card grading and condition evaluation AI via API.
How to Automate Pricing of Cards & Comics via API
A step-by-step guide on how to easily get listings of collectibles, such as comic books, manga, trading card games & sports cards.