How to Train an Object Detection Model With One Click
Define, optimize and deploy to API your custom object detection model without coding.


Introducing Custom Object Detection on Click!
With our newly released object detection, you are able to train models for finding objects on your images. Ximilar solution allows you to combine Recognition and Detection models in one workflow through the Flows service. On click, without a single line of code!
We are glad that you love our Custom Image Recognition service, which helps you effectively build classification and tagging models. Over time, we have received a lot of messages that you are missing a service for training object detection models. We have spent a lot of time on it, and we know why – making your life easier when building such models. Training detection models of good quality can be quite challenging, and we wanted to be sure to deliver the best solution possible.
What Is Object Detection
The difference between recognition and detection is the following: in recognition, we are interested if a feature/item is present on our image. In reality, there could be many of these items in the image and one would like to know their count and positions. This is exactly the task for object detection. Object detection models can predict the exact locations of items in the form of bounding boxes – rectangles around the objects.
If you want to know more about the technology behind it, read the blog post from our ML specialist Libor Vaněk.
Creating Your First Model Step-by-Step
Define Your Task (Model)
Just log in to app.ximilar.com and click on the Object Detection tile on the dashboard. Click on Create New Task and set the name and description (optional). After that, you need to create detection labels and connect them to the Task. Click on Create New Label tile for your first detection label. After doing this, your task definition is complete. Your task now contains one label, but you can create and connect more.
Upload Your Data
Now we need to upload our dataset and create bounding boxes on your images. Go to the Images page and start uploading. Then go through each of the images and create objects/bounding boxes on them.
As with the Image Recognition service, we recommend starting with a small dataset of about 50 images per label and then increasing the counts. If you already have your dataset with bounding boxes on your local computer, you can use Ximilar Client to upload them.
Train the Model and See the Results
Once your training collection is ready, click the TRAIN button on the TASK page. Training will take some time (up to several hours), so make a coffee and relax.
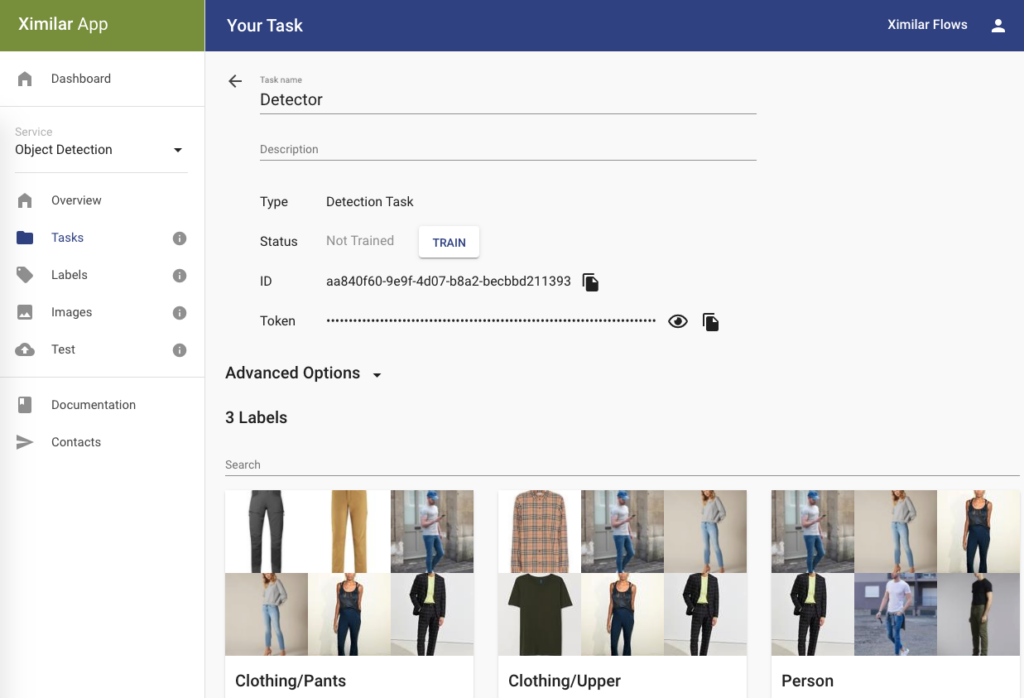
After the model is successfully optimized, you can use the detect endpoint and test it in production or even connect to the API with Ximilar Client.
Upload More Data
There is a good chance that after the first round, your model will require more images and objects. However, you already have some semi-perfect models trained, and you can use them to help you with creating Bounding Boxes on your new training images – just use the Predict button below the training image. If you want, you can create your independent TEST dataset, you can do it by using the test flag. See the video below.
Flows With Object Detection
This is our most powerful feature right now. You can build a really complex computer vision system by connecting detection and recognition models into a single API endpoint. Imagine first detecting individual items on the image and then recognizing their attributes. This is possible with the new Flows action “Object Selector”. What are the example use cases?
- detect all the items on a production line and identify if they have a defect or not
- detect fashion products on the person and recognize all their attributes
- find the exact position and recognize tooth decays
- count and classify all the cars from the parking camera
- object recognition for insurance damage and cost prediction
- and many more
We will go through one of these examples in an upcoming blog post. Follow us on social media [LN | FB | TW | IN] so you will not miss anything important.
Tell Us About Your Ideas
This is one of the best solutions for detecting bounding boxes, which is available in the market. Why choose our solution?
- The UX is great, and we made it really straightforward to use it.
- Great performance with SOTA architectures behind it.
- The price is affordable.
- Download models for offline usage on our higher pricing plans.
- Detect items on your images and then recognize features with image recognition through the Flows service.
- Configure your image augmentation settings for training and get better performance.
- You can A/B test model versions and evaluate the accuracy on an independent dataset.
- We are using it in our own custom services, and we keep it updated with new techniques and architectures 🙂
If you love this new feature, you would like to discuss anything with us, or you have some custom project from computer vision, then contact us, and we can schedule a call with you.

Tags & Themes
Related Articles
Getting Started with Ximilar App: Plan Setup & API Access
Ximilar App is a way to access computer vision solutions without coding and to gain your own authentication key to use them via API.

Get an AI-Powered Trading Card Price Checker via API
Our AI price guide can be used for value tracking of cards and comic books, offering accurate pricing data and their history.

Identify Comic Books & Manga Via Online API
Get your own AI-powered comics and manga image recognition and search tool, accessible through REST API.